Laboratorul 2 (se va intinde pe 2 saptamani)
(Deadline: 26.03.2019 23:59:59)
Daca nu sunteti logati exercitiile nu se mai afiseaza.
Material ajutator pentru acest laborator: Liste-exercitii rezolvate
Exercitii de munca individuala (recapitulare laborator anterior)
Liste
O lista se reprezinta sub forma: [el1,el2,...,eln].
O lista poate cuprinde elemente de tipuri diferite.
Lista [a, 10, 4.5, X, str(a,b), [1,2,3], 1/2] e o lista valida.
Lista vida o notam astfel: [].
O notatie speciala pentru liste este [PrimulElement|RestulListei]. Prin aceasta se separa primul element de celelalte. PrimulElement e chiar primul element din lista pe cand RestulListei reprezinta lista ce contine toate elementele de la al 2-lea incolo (poate fi si vida daca lista initiala continea un singur element, de exemplu [a]=[a|[]]). De obicei notatia este [H|T], unde H vine de la head si T de la tail. Se pot scoate si mai multe elemente inainte de bara verticala, caz in care notatia arata in felul urmator: [H1,H2,...,Hn|T].
Exemple:
| ?- L=[1|[2,3]].
L = [1,2,3] ?
yes
| ?- L=[1,2|[3]].
L = [1,2,3] ?
yes
| ?- L=[1,2,3|[]].
L = [1,2,3] ?
yes
| ?-
O lista nevida e un termen compus:
| ?- compound([a,b,c]).
yes
| ?- compound([a]).
yes
Pe de alta parte o lista vida este un termen simplu:
| ?- compound([]).
no
Aceasta se intampla deoarece modul de scriere al listei, cu paranteze drepte este doar o alta forma de scriere a structurii
.(PrimElement,RestLista), parantezele drepte si virgula fiind de fapt operatori.
| ?- L = .(a,[b,c]).
L = [a,b,c] ?
yes
| ?- L = .(a,[]).
L = [a] ?
yes
Unificarea in cazul listelor
Cum listele sunt elemente compuse, modul de realizare a unificarii este acelasi cu cel al termenilor compusi generali.
Atunci cand scriem listele sub forma desfasurata (adica nu sub forma [H|T], ci cu toate elementele enumerate), unificarea se realizeaza
element de element, asa cum se poate vedea in exemplele de mai jos:
| ?- [1,A,3]=[1,2,B].
A = 2,
B = 3 ?
yes
| ?- [1,2,C]=[2,D,3].
no
| ?-
Cand scriem listele sub forma [H1,...,Hn|T], nu este obligatoriu ca si termenul din stanga si cel din dreapta sa fie scrise astfel.
Prologul, evident, face calculele necesare pentru a realiza unificarea. Iata cateva exemple:
| ?- [H|T]=[1,2,3].
H = 1,
T = [2,3] ?
yes
| ?- [X|[]]=[1].
X = 1 ?
yes
| ?- [X]=[1,2].
no
| ?- [1,2|[3]]=[H|T].
H = 1,
T = [2,3] ?
yes
| ?-
Afisarea unei variabile de tip lista in consola
In Sicstus Prolog
In momentul in care in inteogare apare o variabila de tip lista, valoarea ei calculata va fi afisata in consola ca si pentru celelalte
variabile, insa apare o problema la listele mai lungi (care au mai mult de 10 elemente), cum se poate observa in exemplele simple de interogari
de mai jos unde s-a folosit doar operatorul de unificare =.
| ?- L=[1,2,3].
L = [1,2,3] ?
yes
| ?-
| ?- L=[1,2,3,4,5,6,7,8,9,10].
L = [1,2,3,4,5,6,7,8,9,10] ?
yes
| ?- L=[1,2,3,4,5,6,7,8,9,10,11].
L = [1,2,3,4,5,6,7,8,9,10|...] ?
yes
| ?-
In ultimul exemplu, cel marcat cu galben, lista are mai mult de 10 elemente. In cadrul setarilor default ale sicstus-ului, pentru o lista mai mare de 10 elemente se afiseaza doar primele 10, urmate de |... (observati operatorul |) care simbolizeaza restul listei. Daca dorim sa afisam mai multe elemente din listele mai lungi, trebuie sa intram in meniul de afisare al variabilelor. Putem face asta in urmatorul mod:
| ?- L=[1,2,3,4,5,6,7,8,9,10,11].L = [1,2,3,4,5,6,7,8,9,10|...] ? h
Top-level options:
RET y no more choices
; n more choices
b break
< reset printdepth
< <n> set printdepth
^ reset subterm
^ <n> set subterm
? h print this information
? < 50
L = [1,2,3,4,5,6,7,8,9,10,11] ?
yes
| ?-
In momentul in care ne afiseaza valoarea unei variabile si apare dupa ea simbolul ?, de fapt un prompt care asteapta o comanda, in loc sa dam comenzile obisnuite de enter sau ; pentru a continua sau a opri afisarea solutiilor, vom da optiunea h care afiseaza toate comenzile posibile. Dintre optiunile posibile observam si < <n> set printdepth care, dupa cum ii spune si numele, seteaza adancimea de printare. Si il setam de exemplu la 50, cum se vede si in afisajul de mai sus. Daca vreti sa reveniti la afisarea default puteti scrie doar un < fara numar in dreapta, si atunci va reveni la maximul de 10 elemente.
Mai multe despre liste gasiti in documentatia pentru sicstus prolog.
In SWI Prolog
?- set_prolog_flag(answer_write_options,[max_depth(0)]).Rezolvarea unei probleme cu liste
In majoritatea cazurilor, un exercitiu cu liste se refera ori la generarea unei liste ori la parcurgerea ei si prelucrarea elementelor sale. Unele exercitii pot implica atat generare cat si parcurgere de liste.
Modurile de tratare ale celor doua cazuri sunt foarte asemanatoare. Pseudocodul pentru problemele de parcurgere si evaluare a elementelor
unei liste arata astfel:
pred([H|T], ...alti parametri...):- ... diverse conditii... , evalueaza(H), pred(T, ...), ... .
Practic lista se scrie sub forma [H|T] pentru a izola primul element de restul listei si pentru a-l prelucra, iar apoi restul listei,
T, este trimis intr-un apel recursiv al predicatului, pentru a-i fi evaluate mai departe elementele. Practic T-ul din acest prim pas
recursiv incepe cu al doilea
element al listei si cand ajunge in apelul recursiv sa fie unificat cu o scriere de forma [H1|T1] va fi izolat
si prelucrat primul sau element (adica al doilea din lista initiala). Acest procedeu se repeta pana se ajunge la prelucrarea
ultimului element. In acel apel recursiv lista data ca parametru a ajunss doar cu un element si anume ultimul din lista initiala
si cum stim ca lista [elem]=[elem|[]] urmatorul apel recursiv va fi pentru o lista vida, adica pred([], ...). In acel moment
stim ca evaluarea listei s-a terminat deci trebuie sa oprim si recursivitatea, ceea ce se realizeaza printr-o regula in care
parametrul corespunzator listei este dat sub forma de lista vida, adica:
pred([], ...) :- ... .
pred([], ...) :- ... .
Pseudocodul general pentru rezolvarea problemelor de generare a unei liste:
pred([H|T], ...alti parametri...):- ... diverse conditii... , calculeaza(H), pred(T, ...), ... .
Ce s-a schimbat aici? In loc sa cunoastem lista si sa prelucram valoarea lui H, o calculam. Iar apoi trimitem restul
necunoscut al listei, T, intr-un apel recursiv. In urma primului pas de recursivitate, cand se calculeaza primul element al T-ului
transmis, de fapt se calculeaza elementul de pe a doua pozitie din lista initiala. Procedeul continua pana la calcularea ultimului element.
In acel moment, lista trebuie "inchisa". Pentru a va gandi la acest ultim pas, cel mai simplu e sa va ganditi la cazul particular in care lista
calculata va rezulta intr-o lista cu un singur element. Lista e calculata prin apelul pred([H|T], ...). L-am calculat pe H; dar cat trebuie sa fie
T ca sa avem o lista de un singur element? [H|[]]=[H] deci T ar trebui sa fie egal cu [], motiv pentru care punem acea ultima instructiune:
pred([], ...) :- ... .
pred([], ...) :- ... .
care are intr-adevar rolul de a termina lista.
Studiu de caz: concatenarea a doua liste
Sa luam un exemplu de exercitiu cu liste. Presupunem ca dorim sa construim un predicat care primeste doua liste si realizeaza concatenarea lor intr-o
a treia lista (lista rezultat). Deci predicatul nostru va avea doi parametri de intrare si unul de iesire:
concat(+L1,+L2,-L3)
Pentru a realiza lista rezultat ar trebui sa copiem in ea elementele din prima lista si in urma lor elementele din a doua lista.
Evident, nu putem realiza acest lucru in mod direct, deoarece dintr-o lista, in Prolog, putem accesa in mod direct doar primul element,
prin scrierea [H|T], sau primele n elemente, cu n fixat printr-o scriere de forma [H1,H2,..,Hn|T].
Sa consideram exemplul cu L1=[a,b,c] si L2=[d,e,f]
lista rezultat va fi [a,b,c,d,e,f]:
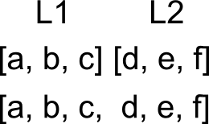
Observam ca lista rezultat are finalul egal cu L2, deci ea ar putea fi unificata cu o scriere de forma [H1,H2,...,Hn|L2], punand astfel lista L2, la final, ca element intreg fara a fi necesar sa-i descoperim elementele. Problema noastra e cu primele elemente, cele din L1, pentru ca nu cunoastem n-ul, nu stim pe caz general cate elemente sunt in prima lista ca sa putem sa le concatenam direct, deci nu putem folosi in mod direct scrierea [H1,H2,...,Hn|L2].
Practic trebuie sa descoperim elementele din L1 mai intai, si asta vom reliza printr-o parcurgere (element de element), deci lista L1
va fi scrisa sub forma: [H|T]. De asemenea mai putem observa din exemplul de mai sus ca primul element din L1
([a,b,c]) e acelasi cu primul element din lista rezultat
([a,b,c,d,e,f]).
Prin urmare concat va avea pasul recursiv de forma:
concat([H|T],L2,[H|Trez]):- concat(T,L2,Trez).
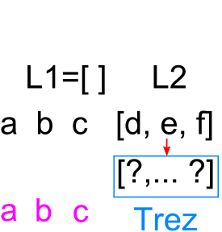
Astfel, pentru exemplu, avem initial datele in formatul urmator:
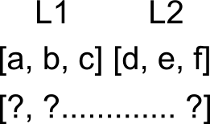
Deci, cand facem interogarea
| ?- concat([a,b,c],[d,e,f],L).
cand va intra in primul pas de recursivitate datele vor fi prelucrate astfel:
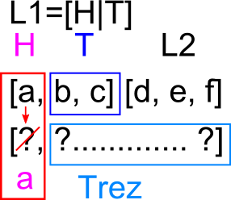
Dupa cum se observa, lista [a,b,c] trimisa ca parametru se unifica in regula recursiva cu primul parametru al lui concat scris sub forma [H|T]
astfel in H ajunge a iar in T lista [b,c]. Cum H a fost folosit si pentru a desemna primul element al listei rezultat,
acesta devine tot a. Apoi prin apelul recursiv concat(T,L2,Trez) practic se face interogarea interna
concat([b,c],[d,e,f],Trez). Cu alte cuvinte din lista L1 de 3 elemente ajungem la lista T de 2 elemente
(care incepe de la al doilea element al lui L1), iar din lista rezultat am calculat primul element, urmand sa calculam si restul elementelor
de la 2 incolo (restul de lista reprezentat prin Trez). Astfel, in urmatorul pas de recursivitate, avem:
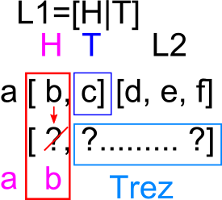
Ca si inainte s-a copiat primul element din prima lista (care e de fapt al doilea element din lista L1) in prima pozitie din sublista
rezultat (spun sublista fiindca ea e de fapt doar o parte din lista rezultat; observati faptul ca a fost practic calculat elementul de
pe pozitia a doua din lista rezultat reala). Iar acum intern se realizeaza apelul concat([c],[d,e,f],Trez)
In pasul al treilea de recursivitate, lista [c] unificata cu [H|T] ajunge [c|[]], deci practic T-ul acum e lista vida.
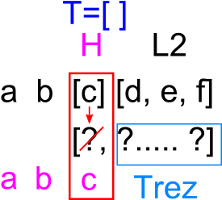
S-a ajuns si la calcularea celui
de-al treilea element din lista reala, insa odata cu acest pas s-au terminat si elementele din prima lista. Ce ramane de facut?
Stim ca in rezultat ar trebui acum sa urmeze a doua lista. Dar prin faptul ca lista rezultat e scrisa drept [H|Trez], unde H-ul e deja calculat
(adica are valoarea c, deci avem rezultatul intermediar [c|Trez]) si cum stim ca Trez trebuie sa contina chiar elementele din lista a doua
putem pur si simplu sa spunem ca Trez e egal cu L2 (adica sa le unificam). Deci rezulta si regula (pasul de oprire):
concat([],L2,L2).
Aceasta regula rezolva si faptul ca nu tratam nicaieri cazul cand prima lista era vida.
In urma pasului 3 apelul intern concat([],[d,e,f],Trez) nu mai poate intra pe regula recursiva deoarece scrierea [H|T] implica o lista cu
cel putin un element, iar primul parametru acum e lista vida. Deci va intra pe regula pas de oprire. Aici prin faptul ca am folosit L2 si pe primul
parametru si pe al doilea practic i-am spus Prologului ca avem in parametrii 2 si 3 acelasi obiect. Cum L2 e instantiat, dar al treilea nu,
cele doua se unifica si la revenirea din apel in pasul 3 recursiv Trez va avea valoarea [d,e,f].
Acum se realizeaza intoarcerea din recursivitate. Apelurile au fost:
concat([a,b,c],[d,e,f],Trez) 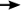 concat([b,c],[d,e,f],Trez)
concat([c],[d,e,f],Trez)
concat([],[d,e,f],Trez)
concat([b,c],[d,e,f],Trez)
concat([c],[d,e,f],Trez)
concat([],[d,e,f],Trez)
cu Trez necunoscut, iar revenirile sunt:
concat([],[d,e,f],[d,e,f]) concat([c],[d,e,f],[c,d,e,f])
concat([b,c],[d,e,f],[b,c,d,e,f])
concat([a,b,c],[d,e,f],[a,b,c,d,e,f])
Predicate predefinite pentru liste, in Sicstus 4
In Sicstus 4 exista cateva predicate predefinite pentru lucrul cu liste:
Predicatul member(?X,?L) verifica daca termenul X se afla in lista L, asa cum se vede in exemplul de mai jos:
| ?- member(b,[a,b,c]).yes
| ?- member(x,[a,b,c]).
no
| ?-
Verificarea se face prin unificare, cu alte cuvinte, daca se poate realiza unificarea dintre X si unul dintre elementele listei, atunci predicatul se termina cu succes. De aceea predicatul member poate fi apelat si cu un X neinstantiat, si atunci va avea ca solutii succesive in X elementele listei:
| ?- member(X,[a,b,c]).X = a ? ;
X = b ? ;
X = c ? ;
no
Datorita faptului ca verificarea se face prin unificare merge si sa selectam din lista elementele care urmeaza un anume format, asa cum se vede in exemplul de mai jos cu termeni compusi:
| ?- member(a(X,Y),[a(1,2),b(2,3), a(3,2,1), a(10,11)]).X = 1,
Y = 2 ? ;
X = 10,
Y = 11 ? ;
no
| ?- | ?- member(X+Y,[3+2,1-1,5+6+7,4+2]).
X = 3,
Y = 2 ? ;
X = 5+6,
Y = 7 ? ;
X = 4,
Y = 2 ? ;
no
| ?- Predicatul member se poate apela si astfel: | ?- member(1,L).
L = [1|_A] ?
yes
| ?
In L se obtine o lista in care primul element este X-ul (in cazul acesta X=1) si coada listei este neinstantiata
Predicatul append(?L1,?L2,?Lrez)
este folosit pentru a concatena doua liste. Daca L1 si L2 sunt instantiate, atunci in Lrez se va calcula concatenarea lor: | ?- append([a,b,c,d],[e,f,g],L).L = [a,b,c,d,e,f,g] ?
yes
Daca Lrez e instantiat iar in L1 se afla un prefix de-al lui Lrez, atunci in L2 se va calcula sufixul lui Lrez, obtinut prin eliminarea inceputului egal cu L1.
| ?- append([a,b,c,d],L2,[a,b,c,d,x,y]).
L2 = [x,y] ?
yes
Daca Lrez e instantiat iar in L2 se afla un sufix de-al lui Lrez, atunci in L1 se va calcula prefixul lui Lrez, obtinut prin eliminarea sfarsitului egal cu L2.
| ?- append(L1,[x,y],[a,b,c,d,x,y]).L1 = [a,b,c,d] ?
yes
| ?-
Daca Lrez e instantiat, dar nici L1 si nici L2 nu sunt instantiate, poate fi folosit si pentru a gasi toate perechile de liste care concatentate dau Lrez.
| ?- append(L1,L2,[b,c,d]).
L1 = [],
L2 = [b,c,d] ? ;
L1 = [b],
L2 = [c,d] ? ;
L1 = [b,c],
L2 = [d] ? ;
L1 = [b,c,d],
L2 = [] ? ;
no
| ?-
Predicatul length(?L,?N) calculeaza in N lungimea unei liste date, L.
| ?- length([a,b,c,d],N).N = 4 ?
yes
| ?-
In unele probleme avem nevoie sa pornim de la o lista de lungime data, dar fara niste valori efective in elemente. Pentru aceasta putem folosi length cu N-ul dat si L-ul neinstantiat:
| ?- length(L,4). L = [_A,_B,_C,_D] ? yes | ?-Un exemplu de folosire a acestei forme. Vrem sa scriem predicatul care ne da prefixul de lungime N dintr-o lista data. De exemplu pentru lista de forma [a,b,c,d,e] si N=3, rezultatul ar fi [a,b,c].
%prefix(+L,+N,-Prefix)
prefix(L,N,Prefix):- length(Prefix,N),append(Prefix,_,L).
Mai sus s-a creat o lista numita Prefix, de N elemente neinstantiate care a fost transmisa lui append. Astfel append a gasit doua liste: una unificata cu Prefix, de lungime N, continand primele N elemente ale lui L si lista cu restul elementelor din L (care nu ne intereseaza, motiv pentru care am folosit _ ).
| ?- prefix([a,b,c,d,e],3,Pref).
Pref = [a,b,c] ?
yes
| ?-
Predicatul sort(+L,-Ls) primeste o lista ca parametru de intrare si calculeaza lista continand elementele din prima lista in ordine crescatoare. De asemenea, elimina si duplicatele
| ?- sort([a,r,z,a,b,c,d],L).L = [a,b,c,d,r,z] ?
yes
| ?-
Siruri de caractere
Sirurile de caractere sunt practic liste de coduri ASCII. Sirurile de caractere se scriu intre ghilimele.
Atentie, nu le confundati cu sirurile intre apostroafe, acelea fiind de fapt atomi.
Observati mai clar diferenta aici:
| ?- X='abc'.
X = abc ?
yes
| ?- X="abc".
X = [97,98,99] ?
yes
Se poate realiza transformarea de la un sir de caractere la un atom (si invers) cu ajutorul unui predicat built-in:
atom_codes(Atom, Sir)
| ?- atom_codes(abc,Sir).
Sir = [97,98,99] ?
yes
| ?- atom_codes(T,"abc").
T = abc ?
yes
De asemenea exista si predicatul
atom_chars(Atom,Lista_caractere)
care pentru un atom dat obtine lista caracterelor ce-l compun, sau invers, fiind data lista, poate obtine atomul respectiv
| ?- atom_chars(abc,L).
L = [a,b,c] ?
yes
| ?- atom_chars(T,[a,b,c]).
T = abc ?
yes
Atentie, nu uitati ca e o diferenta intre sirul "abc" care e o lista de coduri ASCII, deci de numere, si lista de caractere (atomi formati dintr-o singura litera) [a,b,c].
Pentru a obtine caracterul corespunzator unui cod ASCII, si invers pentru a obtine codul ASCII pentru un caracter dat, se foloseste
char_code(Caracter,Cod)
| ?- char_code(a,C).
C = 97 ?
yes
Asa cum e atom_chars pentru atomi, exista un predicat similar si pentru numere:
number_chars
| ?- number_chars(1234,L).
L = ['1','2','3','4'] ?
yes
| ?- number_chars(12.5,L).
L = ['1','2','.','5'] ?
yes
| ?- number_chars(-12.5,L).
L = [-,'1','2','.','5'] ?
yes
| ?-
Atentie, primul parametru trebuie sa fie neaparat numar. Nu va accepta un atom format doar din caractere numerice:
| ?- number_chars('1234',L).! Type error in argument 1 of number_chars/2
! expected a number, but found '1234'
! goal: number_chars('1234',_114)
| ?-
Similar, echivalentul lui atom_codes, dar pentru numere, este
number_codes
L = [45,49,50,46,53] ?
yes
| ?-
Ca sa concatenam doi atomi folosim atom_concat(+Atom1,+Atom2,-AtomiConcatenati).
Rez = abcdef ?
yes
Predicatul atom_concat poate fi folosit si sub forma atom_concat(-Atom1,-Atom2,+Atom) si calculeaza in Atom1 si Atom2 toate variantele de atomi care prin concatenare ar fi rezultat in al treilea parametru.
A1 = '',
A2 = xy ? ;
A1 = x,
A2 = y ? ;
A1 = xy,
A2 = '' ? ;
no
| ?-
Avem si un predicat care calculeaza lungimea unui atom: atom_length(+Atom,-Lungime)
| ?- atom_length(abc, N).
N = 3 ?
yes
| ?-
Stim ca atomii si numerele sunt tipuri de date diferite si anumiti operatori pot fi folositi doar cu numere, iar altii doar cu atomi. Asadar uneori avem nevoie sa transforma un numar in atom, alteori, vrem sa transformam un atom in numar:
%conversie_nr_atom(+Nr,-Atom)
si vedem mai jos cum functioneaza conversiile:
| ?- conversie_nr_atom(100,A).
conversie_nr_atom(Nr,Atom):-number_chars(Nr,Lchr),atom_chars(Atom,Lchr).
%conversie_atom_nr(+Atom,-Nr)
conversie_atom_nr(Atom,Nr):- atom_chars(Atom,Lchr),number_chars(Nr,Lchr).
A = '100' ?
yes
| ?- conversie_atom_nr('100',N).
N = 100 ?
yes
Observatie: Adesea veti intalni o notatie de forma nume_predicat/numar. Numarul respectiv reprezinta numarul de parametri corespunzatori predicatului. Doua predicate cu acelasi nume dar cu numere diferite de parametri sunt predicate diferite.
Operatorul =..
In partea stanga trebuie sa aiba o structura iar in partea dreapta o lista.
Poate fi folosit pentru a desparti o structura intr-o lista ce are ca prim element numele structurii,
iar ca elemente urmatoare argumentele structurii, sau invers poate primi o lista pe care sa o transforme intr-o structura. De exemplu:
| ?- ab(1,2,3)=..L.
L = [ab,1,2,3] ?
yes
| ?- X=..[ab,1,2,3].
X = ab(1,2,3) ?
yes
| ?- ab(1,2,3)=..[ab,1,2,3].
yes
| ?-
Putem avea in partea stanga si structuri compuse, formate cu ajutorul operatorilor:
| ?- 2*4-8 =.. L.
L = [-,2*4,8] ?
yes
| ?-
| ?- X=.. [+, 2, 3].
X = 2+3 ?
yes
| ?-
In partea din stanga sunt acceptati si termeni simpli, caz in care lista din dreapta va contine un singur element (egal in valoare cu termenul simplu din partea stanga a operatorului):
| ?- a =.. L.
L = [a] ?
yes
| ?- 2 =.. L.
L = [2] ?
yes
| ?- X =.. [a].
X = a ?
yes
| ?-
Predicate de I/O pentru consola
Predicatul
read(-Termen)
citeste un termen de la tastura si realizeaza unificarea dintre acesta si variabila data ca parametru al lui read.
Citirea se face pana la intalnirea unui punct.
| ?- read(X).
|: 3.
X = 3 ? yes
| ?- read(X).
|: 'ceva intre apostroafe'.
X = 'ceva intre apostroafe' ? yes
(yes apare imediat dupa semnul intrebarii deoarece enter-ul introdus dupa punct ramane in bufferul consolei
si e transmis atunci cand afiseaza solutia, ca si cum am fi dat enter dupa afisarea solutiei).
Se pot citi si termeni compusi:
| ?- read(X),X=t(Y).
|: t(a).
X = t(a),
Y = a ? yes
| ?-
Sau:
| ?- read(a(X)).
|: a(5).
X = 5 ? yes
| ?-
Putem citi in acest mod inclusiv expresii formate cu operatori:
| ?- read(X+Y).|: 2+3.
X = 2,
Y = 3 ? yes
Evident, merge sa facem asta numai daca termenul primit de read se poate unifica cu ceea ce citeste de la tastatura:
| ?- read(X+Y).|: 7.
no
| ?-
Tot un predicat de citire este si Desi citeste doar un caracter, Un predicat foarte asemanator cu get_char este si Predicatul
Predicatul
Predicatul
Nu exista un predicat predefinit care sa curete consola, si pana de curand chiar credeam ca nu se poate face acest lucru,
dar am gasit definitia unui predicat, care poate face asta, pe o
lista de discutii.
Predicatul foloseste get_char(-Chr). Acesta citeste insa, nu pana la punct, ci doar un caracter.
| ?- get_char(X).
|: a
X = a ? yes
| ?-
get_char asteapta apasarea tastei enter. Astfel chiar daca intorducem mai multe caractere, asa cum se vede in exemplul de mai jos, predicatul se va termina dupa ce apasam enter si va unifica termenul dat ca parametru doar cu primul caracter din sirul intordus de la tastatura.
|: abc
X = a ? % Break level 1
% 1
| ?-
get_code(-Chr). Acesta citeste codul ASCII al caracterului introdus de la tastatura, si ca si get_char citeste dupa ce s-a apasat tasta enter.
|: a
X = 97 ? yes
| ?- get_code(X).
|: abc
X = 97 ? % Break level 1
% 1
| ?-
write(+Termen)
scrie valoarea acelui termen in consola. Write nu primeste ca argument decat un singur termen, deci daca dorim sa afisam
mai multe valori va trebui sa folosim cate un write pentru fiecare. Termenii pot contine caractere escape precum \n, \t etc.
| ?- write(3).
3
yes
| ?- write('miau miau').
miau miau
yes
| ?- write('miau\nmiau').
miau
miau
yes
nl
afiseaza o linie noua.
format(+Termen_de_afisat,+Lista_argumente)
afiseaza termenul din primul parametru inlocuind secventele de tipul ~cod cu argumentele corespunzatoare
din lista data ca al doilea parametru. Codurile sunt asemanatoare celor acceptate de functia printf din C, de
exemplu in loc de %d, avem ~d, in loc de %s, avem ~s etc. La acestea se mai adauga cateva coduri specifice prologului.
| ?- format('Un exemplu de lista: ~p cu ~d elemente',[[a,b,c],3]).
Un exemplu de lista: [a,b,c] cu 3 elemente
yes
Curatarea ecranului consolei
format si are urmatoarea definitie:
Pentru a intelege mai bine de unde vin codurile respective,
puteti citi despre secventele escape de control pentru terminale ANSI.
Consola prolog respecta standardul ANSI deci suporta si ea aceste coduri.
Secventa 0x1b reprezinta codul caracterului ESC scris in hexa (observati prefixul 0x).
Codul <ESC>[H conform linkului mai devreme precizat muta cursorul pe pozitia de home a consolei
(in coltul din stanga sus). Codul <ESC>[2J sterge ecranul si muta cursorul inapoi la home-ul consolei.
De fapt din ce am testat am vazut ca merge scris direct:
Prin urmare va puteti defini un predicat:
Exemple si exercitii rezolvate cu liste
In sectiunea de mai jos avem cateva exemple si exercitii rezolvate, impeuna cu explicatii referitoare la cod.
Predicat care verifica daca un termen este lista
Din enuntul exercitiului ne dam seama ca avem un singur parametru, si este de intrare. Deci specificatia predicatului va fi:
%e_lista(+Lista)
Lista vida e un caz particular de lista. Si apoi avem si cazul general de lista, cu cel putin un element (fapt evidentiat prin forma [H|T]). Deci sa scriem cele doua cazuri:
e_lista(L):- L=[]; L=[_ | _].
Si observam ca merge si pe caz general si pe caz particular:
| ?- e_lista([]).yes
| ?- e_lista([1,2,3]).
yes
Predicat care calculeaza lungimea unei liste
Este clar ca avem nevoie de un parametru de intrare (lista) si un parametru de iesire (lungimea acesteia):
%lungime_lista(+Lista,-Lungime)
Pentru o lista scrisa sub forma [H|T] lungimea listei este lungimea lui T la care se aduna 1 (elementul H). Astfel ajungem la o forma recursiva pe care o scriem in prolog:
lungime_lista([_|T],Lg):- lungime_lista(T,LgT), Lg is LgT+1.
Totusi tot eliminand cate un element pentru a calcula la fiecare pas lungimea T-ului, se termina elementele din lista si ajungem la pasul de oprire, cu lista vida:
| ?- lungime_lista([a,b,c,d],Lungime).Lungime = 4 ?
yes
Predicat care calculeaza suma unei liste
Vom porni de la premisa ca lista contine doar numere. Avem nevoie de un predicat cu un parametru de intrare (lista) si un parametru de iesire, suma. Prin urmare, specificatia predicatului va fi:
%sum_lista(+Lista,-Suma)
Ca de obicei, trebuie sa gasim o formul recursiva avand in vedere si faptul ca avem acces la primul element dintr-o lista si la restul listei, prin scrierea [H|T]. Astfel matematic vorbind suma([H|T])=H+suma(T).
Sa scriem acest lucru si in prolog:
sum_lista([H|T],Suma):- sum_lista(T,SumaT),Suma is SumaT+H.
Variabila SumaT reprezinta suma elementelor din T (restul listei) si e calculata prin apelul recursiv. Variabila Suma reprezinta suma pentru lista [H|T], deci va fi egala cu H adunat cu SumaT.
Ca de obicei, avem nevoie si de un pas de oprire. Tot mergand in restul listei (izoland primul element, H, si transmitand mereu T-ul ca parametru), lungimea listei la fiecare nou apel recursiv scade cu 1, pana cand se termina toate elementele (si ajungem la lista vida). Deci pasul de oprire va fi:
sum_lista([],0).
care e si cazul particular de suma pentru lista vida (suma elementelor unei liste vide e 0).
Sa observam si o interogare:
| ?- sum_lista([3,7,1,0,5,2],S).
S = 18 ?
yes
Predicat care sterge primul element dintr-o lista, egal cu o valoare data
Predicatul trebuie sa primeasca lista si elementul de sters, deci va avea doi parametri de intrare. De asemenea are nevoie si de un parametru de iesire pentru noua lista (rezultata din lista initiala prin stergerea elementului). Specificatia predicatului va fi:
%sterge_elem(+Lista,+Elem,-ListaNoua)
Pentru a sterge elementul trebuie sa parcurgem lista pana cand gasim valoarea cautata. Lista de parcurs o scriem sub forma [H|T]. Daca elementul cautat e chiar primul element din lista, adica H, atunci lista noua (cu elementul eliminat este chiar T):
sterge_elem([E|T],E,T):- !.
Operatorul cut a fost pus ca sa nu mai testam si pe cazul al doilea daca primul element al listei e diferit de H. Cut opreste backtrackingul deci si trecerea la cazul urmator.
Forma recursiva va fi:
sterge_elem([H|T],E,[H|Trez]):-sterge_elem(T,E,Trez).
Astfel, daca H nu este E inseamna ca il putem copia in lista rezultat. Deci lista rezultat va fi [H|Trez]. Practic, daca nu am sters elementul aici, inseamna ca trebuie sa il cautam mai departe in T si sa il stergem de acolo. T-ul din care e sters elementul E este de fapt Trez.
Interogarea va fi: | ?- sterge_elem([a,b,c],b,Lnou). Lnou = [a,c] ? yes | ?-
Observatie: cut-ul din pasul de oprire e foarte important. Daca intr-o interogare cu o lista care cuprinde de doua ori elementul de sters, am cere o noua solutie scriind n dupa prompt:
| ?- sterge_elem([b,a,b,c],b,Lnou).
Lnou = [a,b,c] ? n
no
ar rezulta no, adica [a,b,c] e singura solutie (ceea ce e corect).
Insa, fara cut, daca am avea pasul de oprire doar:
sterge_elem([E|T],E,T).
am avea doua solutii pe inputul dat:
| ?- sterge_elem([b,a,b,c],b,Lnou).
Lnou = [a,b,c] ? ;
Lnou = [b,a,c] ? ;
no
Practic toate listele posibile care rezulta prin eliminarea unei aparitii a elementului de sters (deci nu doar de pe prima pozitie, ci de pe fiecare pozitie in care apare, pe rand)
Predicat care obtine multimea de elemente asociata unei liste ("sterge" duplicatele)
Avem nevoie de un predicat care are un parametru de intrare corespunzator listei si un parametru de iesire corespunzator "multimii" (adica listei fara duplicate).
%multime(+Lista, -Multime)
Pentru a calcula lista M a elementelor distincte ale lui L este clar ca la adaugarea unui element in lista rezultat trebuie sa verificam daca nu exista deja acolo:
multime([H|T],M):- multime(T,MT),
(\+member(H,MT),!,M=[H|MT]; M=MT).
Pasul de oprire:
multime([],[]).
Un exemplu de interogare ar fi:
| ?- multime([a,b,b,a,c,b,c],M).
M = [a,b,c] ?
yes
Predicat care obtine intersectia pentru doua multimi
%intersectie_multimi(+M1,+M2,-Intersectie)
intersectie_multimi([H|M1],M2,Intersectie):- intersectie_multimi(M1,M2,IntersectieAux), (member(H,M2),!, Intersectie=[H|IntersectieAux]; Intersectie=IntersectieAux).
intersectie_multimi([],_,[]).
| ?- intersectie_multimi([a,b,c,d],[x,b,a,y],L).L = [a,b] ?
yes
Predicat care obtine reuniunea pentru doua multimi
%reuniune_multimi(+M1,+M2,-Reuniune)
reuniune_multimi([H|M1],M2,Reuniune):- reuniune_multimi(M1,M2,ReuniuneAux), (\+member(H,M2),!, Reuniune=[H|ReuniuneAux]; Reuniune=ReuniuneAux).
reuniune_multimi([],M2,Reuniune):- Reuniune = M2.
| ?- reuniune_multimi([a,b,c,d],[x,b,a,y],L).L = [c,d,x,b,a,y] ?
yes
Predicat care obtine diferenta dintre doua multimi
%diferenta_multimi(+M1,+M2,-Rez)
diferenta_multimi([H|M1],M2,Rez):-diferenta_multimi(M1,M2,Rez_aux),
(\+member(H,M2),!, Rez=[H|Rez_aux]; Rez=Rez_aux).
diferenta_multimi([],_,[]).
| ?- diferenta_multimi([a,b,c,d],[x,b,a,y],L).L = [c,d] ?
yes
Predicat care transforma literele mici ale unui atom in litere mari
%caps(+Atom,-AtomNou)
caps(Atom, AtomNou):-atom_chars(Atom,Lchr),caps_lista(Lchr,Lcaps), atom_chars(AtomNou,Lcaps).
caps_lista([Litera|T],[LiteraCaps|Tcaps]):- transforma_litera(Litera,LiteraCaps),caps_lista(T,Tcaps).
caps_lista([],[]).
transforma_litera(Litera,LiteraCaps):- a @=<Litera, Litera @=< z, !, name(Litera, [CodLitera]), CodCaps is CodLitera-32, name(LiteraCaps,[CodCaps]) ; LiteraCaps=Litera.
| ?- caps(abc,A).A = 'ABC' ?
yes
| ?- caps(aBc,A).
A = 'ABC' ?
yes
| ?- caps(aB123cdef_g,A).
A = 'AB123CDEF_G' ?
yes
| ?-
Predicat care aduna unele cu altele elementele (de pe aceleasi pozitii) din doua liste, punand rezultatele intr-o a treia lista
%aduna_elemente(+L1,+L2,-Lsum)
aduna_elemente([H1|T1],[H2|T2],[Hsum|Tsum]):-Hsum is H1 + H2, aduna_elemente(T1,T2,Tsum).
aduna_elemente([],[],[]).
| ?- aduna_elemente([2,10,1,4],[3,0,1,9],L).L = [5,10,2,13] ?
yes
Predicat care combina unele cu altele elementele (de pe aceleasi pozitii) din doua liste de termeni compusi, punand rezultatele intr-o a treia lista
Compunerea intre doua structuri vrem sa fie in felul urmator: numele structurilor sa se concateneze iar parametrii structurilor sa se adune intr-o singura lista de parametri pentru structura cu numele compus. De exemplu din a(1,2) si b(2,3) sa obtinem structura ab(1,2,2,3).
Astfel, predicatul va parcurge in paralel listele, combinand la fiecare pas un element din prima lista cu un elementul corespunzator din a doua lista.
De exemplu, daca avem listele [a(1),b(2,3)] si [x(0,a), y(100)] lista rezultata va fi [ax(1,0,a),by(2,3,100)]
combina_termeni([H1|T1],[H2|T2],[Hnou|Tnou]):-combina(H1,H2,Hnou),combina_termeni(T1,T2,Tnou).
| ?- combina(a(10,2),b(3),X).
combina_termeni([],[],[]).
combina(H1,H2,Hnou):- H1=..[Nume1|Param1],H2=..[Nume2|Param2],atom_concat(Nume1,Nume2, NumeNou),append(Param1,Param2,ParamNou),Hnou=..[NumeNou|ParamNou].
X = ab(10,2,3) ?
yes
Predicat care primeste o lista de atomi si ii concateneaza intr-un singur atom
%atom_concat_lista(+Lista,-Atom)
atom_concat_lista([], '').
atom_concat_lista([H|T],A):- atom(H),atom_concat_lista(T,AT), atom_concat(H,AT, A).
| ?- atom_concat_lista(['abc','def','xyz'],A).A = abcdefxyz ?
yes
| ?- atom_concat_lista([],A).
A = '' ?
yes
| ?- atom_concat_lista([abc],A).
A = abc ?
yes